

metadata
dataset_info:
features:
- name: sample_id
dtype: string
- name: task
dtype: string
- name: embodiments
list: string
- name: image
dtype: image
- name: segmentation_mask
list:
list: int64
- name: ground_truth
struct:
- name: Bicycle
list:
list:
list: float64
- name: Human
list:
list:
list: float64
- name: Legged Robot
list:
list:
list: float64
- name: Wheeled Robot
list:
list:
list: float64
- name: category
list: string
- name: context
dtype: string
- name: metadata
struct:
- name: city
dtype: string
- name: country
dtype: string
- name: lighting_conditions
dtype: string
- name: natural_structured
dtype: string
- name: task_type
dtype: string
- name: urban_rural
dtype: string
- name: weather_conditions
dtype: string
splits:
- name: validation
num_bytes: 6117774314
num_examples: 502
- name: test
num_bytes: 6123246091
num_examples: 500
download_size: 344928365
dataset_size: 12241020405
configs:
- config_name: default
data_files:
- split: validation
path: data/validation-*
- split: test
path: data/test-*
tags:
- image
- text
- navigation
pretty_name: NaviTrace
license: cc-by-4.0
task_categories:
- visual-question-answering
- robotics
language:
- en
size_categories:
- 1K<n<10K
NaviTrace
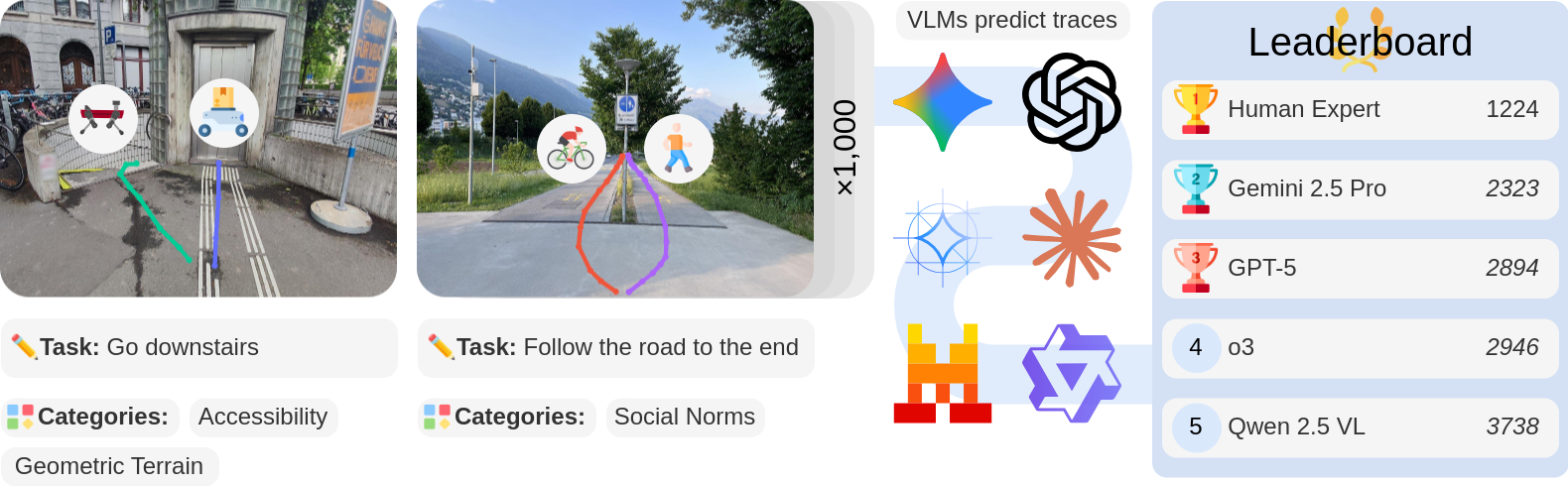
NaviTrace is a novel VQA benchmark for VLMs that evaluates models on their embodiment-specific understanding of navigation across challenging real-world scenarios.
Key Features
- ✏️ Core Task: Given a real-world image in first-person perspective, a language instruction, and an embodiment type, models should predict a 2D navigation path in image space that solves the instruction.
- 🤖 Embodiments: Four embodiment types capturing distinct physical and spatial constraints (human, legged robot, wheeled robot, or bicycle).
- 📏 Scale: 1,002 diverse real-world scenarios and over 3,000 expert-annotated traces.
- ⚖️ Splits:
- Validation split (~50%) for experimentation and model fine-tuning.
- Test split (~50%) with hidden ground-truths for public leaderboard evaluation.
- 🔎 Annotation Quality: All images and traces manually collected and labeled by human experts.
- 🏅 Evaluation Metric: Semantic-aware Trace Score, combining Dynamic Time Warping distance, goal endpoint error, and embodiment-conditioned semantic penalties.
Uses
Run Benchmark
We provide a notebook with example code on how to run this benchmark with an API model. You can use this as a template to adapt to your own model. Additionally, we host a public leaderboard where you can submit your model's results.
Model Training
You can use the validation split to fine-tune models for this task.
Load the dataset with dataset = load_dataset("leggedrobotics/NaviTrace") and use dataset["validation"] for training your model.
See the next section for details on the dataset columns.
Structure
| Column | Type | Description |
|---|---|---|
| sample_id | str |
Unique identifier of a scenario. |
| task | str |
Language instruction (English) solvable purely from the visual information, emphasizing cases where different embodiments behave differently, while still reflecting everyday scenarios. |
| embodiments | List[str] |
All embodiments ("Human", "Legged Robot", "Wheeled Robot", "Bicycle") suitable for the task. |
| image | PIL.Image |
First-person image of a real-world environment with blured faces and license plates. |
| segmentation_mask | List[List[int]] |
Semantic segmentation mask of the image generated with the Mask2Former model. |
| ground_truth | dict[str, Optional[List[List[List[float]]]]] |
A dict mapping an embodiment name to a sequence of 2D points in image coordinates that describes a navigation path solution. One path per suitable embodiment, and multiple paths if equally valid alternatives exist (e.g., avoiding an obstacle from the left or right). If an embodiment is not suitable for the task, the value is None. |
| category | List[str] |
List with one or more categories ("Semantic Terrain", "Geometric Terrain", "Stationary Obstacle", "Dynamic Obstacle", "Accessibility", "Visibility", "Social Norms") that describe the main challenges of the navigation task. |
| context | str |
Short description of the scene as bullet points separated with ";", including the location, ongoing activities, and key elements needed to solve the task. |
| metadata | dict[str, str] |
Additional information about the scenario: - "country": The image's country of origin. - "city": The image's city of origin or "GrandTour Dataset" if the image comes from the Grand Tour dataset. - "urban_rural": "Urban", "Rural", or "Mixed" depending on the image's setting. - "natural_structured": "Structured", "Natural", or "Mixed" depending on the image's environment. - "lighting_conditions": "Night", "Daylight", "Indoor Lighting", or "Low Light" depending on the image's lighting. - "weather_conditions": "Cloudy", "Clear", "Rainy", "Unknown", "Foggy", "Snowy", or "Windy" depending on the image's weather. - "task_type": Distinguishes between instruction styles. Goal-Directed tasks ("Goal") specify the target explicitly (e.g., “Go straight to the painting.”), while Directional tasks ("Directions") emphasize the movement leading to it (e.g., “Move forward until you see the painting.”). Since this is ambiguous sometimes, there are also mixed tasks ("Mixed"). |
Citation
If you find this dataset helpful for your work, please cite us with:
BibTeX:
@article{Windecker2025NaviTrace,
author = {Tim Windecker and Manthan Patel and Moritz Reuss and Richard Schwarzkopf and Cesar Cadena and Rudolf Lioutikov and Marco Hutter and Jonas Frey},
title = {NaviTrace: Evaluating Embodied Navigation of Vision-Language Models},
year = {2025},
month = {October},
journal = {Preprint submitted to arXiv},
note = {Currently a preprint on arXiv (arXiv:2510.26909). Awaiting peer review and journal submission.},
doi = {},
url = {https://arxiv.org/abs/2510.26909},
eprint={2510.26909},
archivePrefix={arXiv},
primaryClass={cs.RO},
}