
Upload 5 files
Browse files- README.en.md +18 -0
- README.es.md +16 -0
- README.eu.md +16 -0
- app.py +84 -0
- requirements.txt +5 -0
README.en.md
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Image2OCR
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
## Slow
|
| 6 |
+
|
| 7 |
+
If you get this message, it will take a long time.
|
| 8 |
+
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
|
| 9 |
+
|
| 10 |
+
## Contributions
|
| 11 |
+
|
| 12 |
+
Contributions are always welcome!
|
| 13 |
+
|
| 14 |
+
## Donations
|
| 15 |
+
|
| 16 |
+
[](https://www.buymeacoffee.com/Artgen)
|
| 17 |
+
|
| 18 |
+
|
README.es.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Image2OCR (imágene a reconocimiento óptico de caracteres)
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
## Lento
|
| 6 |
+
|
| 7 |
+
Si recibes este mensaje, tomará mucho tiempo.
|
| 8 |
+
Ni CUDA ni MPS están disponibles; se está utilizando la CPU por defecto. Nota: Este módulo es mucho más rápido con una GPU.
|
| 9 |
+
|
| 10 |
+
## Contribuciones
|
| 11 |
+
|
| 12 |
+
¡Las contribuciones son siempre bienvenidas!
|
| 13 |
+
|
| 14 |
+
## Donaciones
|
| 15 |
+
|
| 16 |
+
[](https://www.buymeacoffee.com/Artgen)
|
README.eu.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Image2OCR
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
## Mantxo
|
| 6 |
+
|
| 7 |
+
Mezu hau jasotzen baduzu, luze joko du.
|
| 8 |
+
Ez CUDA ez MPS ezin dira ordaindu. Modulu hau askoz azkarragoa da GPU batekin.
|
| 9 |
+
|
| 10 |
+
## Kredituak
|
| 11 |
+
|
| 12 |
+
Kredituak beti dira ongi etorriak!
|
| 13 |
+
|
| 14 |
+
## Donazioak
|
| 15 |
+
|
| 16 |
+
[](https://www.buymeacoffee.com/Artgen)
|
app.py
ADDED
|
@@ -0,0 +1,84 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
@author: idoia lerchundi
|
| 3 |
+
"""
|
| 4 |
+
import urllib.request
|
| 5 |
+
from PIL import Image,ImageFile
|
| 6 |
+
import streamlit as st
|
| 7 |
+
import numpy as np
|
| 8 |
+
import requests
|
| 9 |
+
from io import BytesIO
|
| 10 |
+
import easyocr as ocr
|
| 11 |
+
|
| 12 |
+
def local_css(file_name):
|
| 13 |
+
with open(file_name) as f:
|
| 14 |
+
st.markdown(f"<style>{f.read()}</style>", unsafe_allow_html=True)
|
| 15 |
+
|
| 16 |
+
st.set_page_config(
|
| 17 |
+
page_title="Streamlit iCodeIdoia - OCR an IMAGE - Extract text from an image",
|
| 18 |
+
page_icon="images/ilpicon1.png",layout="wide",initial_sidebar_state="expanded"
|
| 19 |
+
)
|
| 20 |
+
|
| 21 |
+
st.image("images/banner.jpg")
|
| 22 |
+
|
| 23 |
+
# ---- LOAD
|
| 24 |
+
local_css("styles/style.css")
|
| 25 |
+
|
| 26 |
+
@st.cache_resource
|
| 27 |
+
def load_model():
|
| 28 |
+
reader = ocr.Reader(['en'],model_storage_directory='.')
|
| 29 |
+
return reader
|
| 30 |
+
|
| 31 |
+
reader = load_model() #load model
|
| 32 |
+
|
| 33 |
+
# ---- TABS
|
| 34 |
+
tab1, tab2 = st.tabs(["Demo","Application"])
|
| 35 |
+
|
| 36 |
+
with tab1:
|
| 37 |
+
# Handle first image
|
| 38 |
+
|
| 39 |
+
url = "https://https://raw.githubusercontent.com/webdevserv/images_video/main/ocr_sample.jpg"
|
| 40 |
+
|
| 41 |
+
st.subheader("OCR an image demo")
|
| 42 |
+
img_description = st.text('Image text will extracted using OCR.')
|
| 43 |
+
|
| 44 |
+
if st.button('OCR Demo'):
|
| 45 |
+
response = requests.get(url)
|
| 46 |
+
img = Image.open(BytesIO(response.content))
|
| 47 |
+
st.image(input_image) #display image
|
| 48 |
+
img.load()
|
| 49 |
+
st.image(img) #display image
|
| 50 |
+
|
| 51 |
+
with st.spinner("🔄 OCR in process."):
|
| 52 |
+
result = reader.readtext(np.array(img))
|
| 53 |
+
result_text = [] #empty list
|
| 54 |
+
for text in result:
|
| 55 |
+
result_text.append(text[1])
|
| 56 |
+
|
| 57 |
+
st.write(result_text)
|
| 58 |
+
st.balloons()
|
| 59 |
+
else:
|
| 60 |
+
st.write("Upload an image to extract text using OCR.")
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
with tab2:
|
| 64 |
+
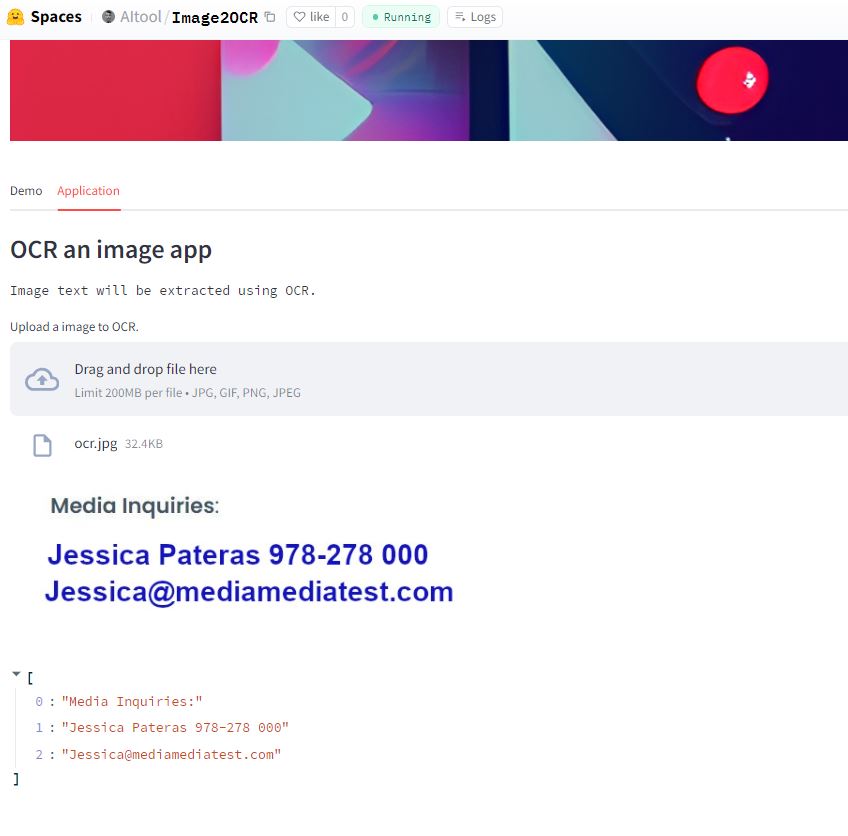
st.subheader("OCR an image app")
|
| 65 |
+
img_description = st.text('Image text will be extracted using OCR.')
|
| 66 |
+
uploaded_file = st.file_uploader("Upload a image to OCR.", type=['jpg'])
|
| 67 |
+
|
| 68 |
+
if uploaded_file is not None:
|
| 69 |
+
img = Image.open(uploaded_file)
|
| 70 |
+
img.load()
|
| 71 |
+
st.image(img) #display image
|
| 72 |
+
|
| 73 |
+
with st.spinner("🔄 OCR in process."):
|
| 74 |
+
result = reader.readtext(np.array(img))
|
| 75 |
+
|
| 76 |
+
result_text = [] #empty list for results
|
| 77 |
+
|
| 78 |
+
for text in result:
|
| 79 |
+
result_text.append(text[1])
|
| 80 |
+
|
| 81 |
+
st.write(result_text)
|
| 82 |
+
st.balloons()
|
| 83 |
+
else:
|
| 84 |
+
st.write("Upload an image to extract text using OCR.")
|
requirements.txt
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
streamlit
|
| 2 |
+
opencv-python-headless
|
| 3 |
+
numpy
|
| 4 |
+
easyocr
|
| 5 |
+
Pillow
|