
metadata
license: apache-2.0
base_model:
- Qwen/Qwen-Image-Edit
pipeline_tag: image-to-image
tags:
- gguf-connector
- gguf-node
widget:
- text: >-
remove all UI text elements from the image. Keep the feeling that the
characters and scene are in water. Also, remove the green UI elements at
the bottom
output:
url: workflow-demo1.png
- text: >-
the anime girl with massive fennec ears is wearing cargo pants while
sitting on a log in the woods biting into a sandwitch beside a beautiful
alpine lake
output:
url: workflow-demo2.png
- text: >-
the anime girl with massive fennec ears is wearing a maid outfit with a
long black gold leaf pattern dress and a white apron mouth open holding a
fancy black forest cake with candles on top in the kitchen of an old dark
Victorian mansion lit by candlelight with a bright window to the foggy
forest and very expensive stuff everywhere
output:
url: workflow-demo3.png
qwen-image-edit-gguf
- use 8-step (lite-lora auto applied); save up to 70% loading time
- run it with
gguf-connector; simply execute the command below in console/terminal
ggc q6
GGUF file(s) available. Select which one to use:
- qwen-image-edit-iq4_nl.gguf
- qwen-image-edit-q2_k.gguf
- qwen-image-edit-q4_0.gguf
- qwen-image-edit-q8_0.gguf
Enter your choice (1 to 4): _
- opt a
gguffile in your current directory to interact with; nothing else
run it with gguf-node via comfyui
- drag qwen-image-edit to >
./ComfyUI/models/diffusion_models - *anyone below, drag it to >
./ComfyUI/models/text_encoders - drag pig [254MB] to >
./ComfyUI/models/vae
*note: option 1 (pig quant) is an all-in-one choice; for option 2 (llama.cpp quant), you need to prepare both text-model and mmproj-clip; option 3 (llama.cpp quant) is an experimental attempt, a merge (text+mmproj), similar to option 1, an all-in-one choice also but pig x llama.cpp crossover

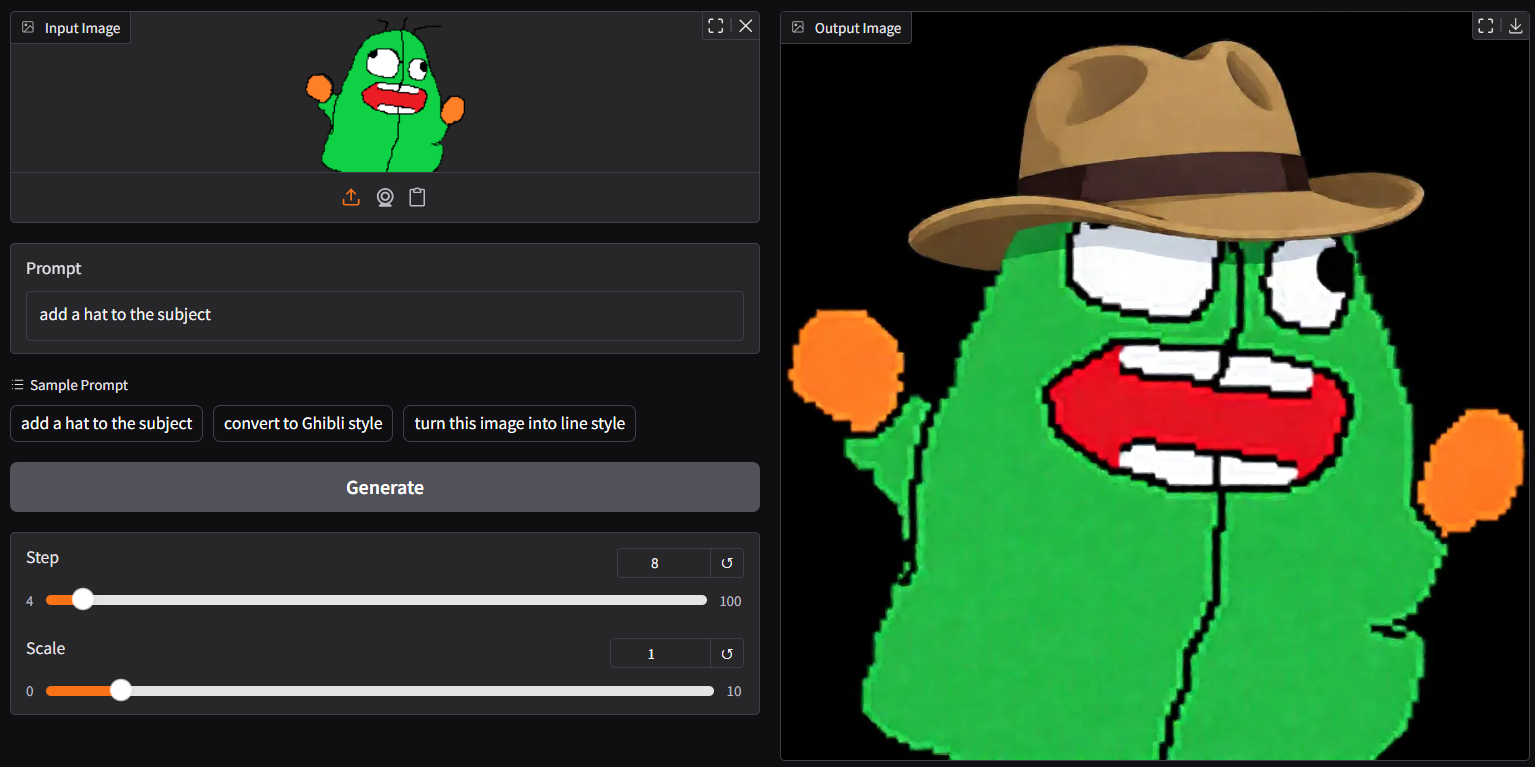
- Prompt
- remove all UI text elements from the image. Keep the feeling that the characters and scene are in water. Also, remove the green UI elements at the bottom

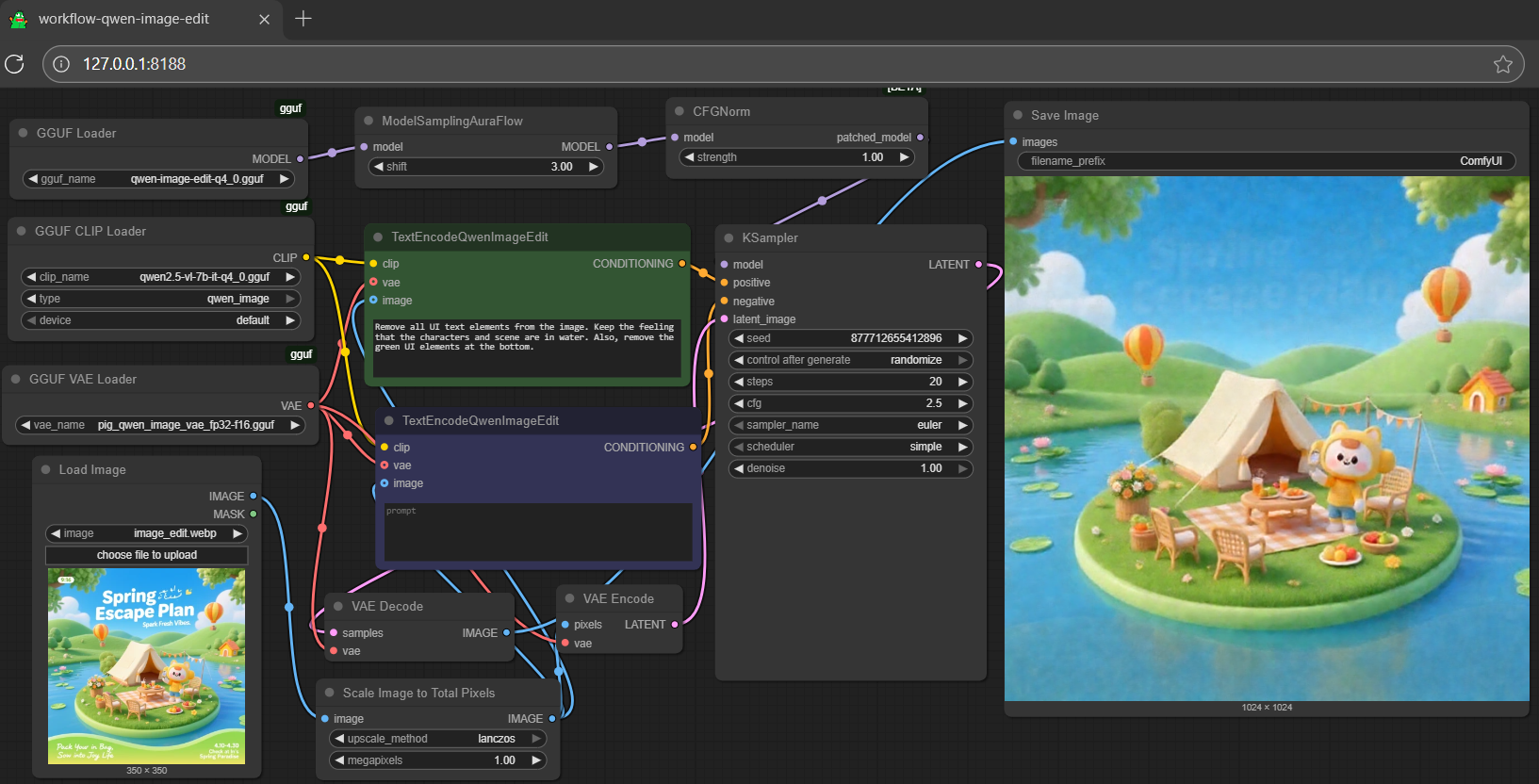
- Prompt
- the anime girl with massive fennec ears is wearing cargo pants while sitting on a log in the woods biting into a sandwitch beside a beautiful alpine lake

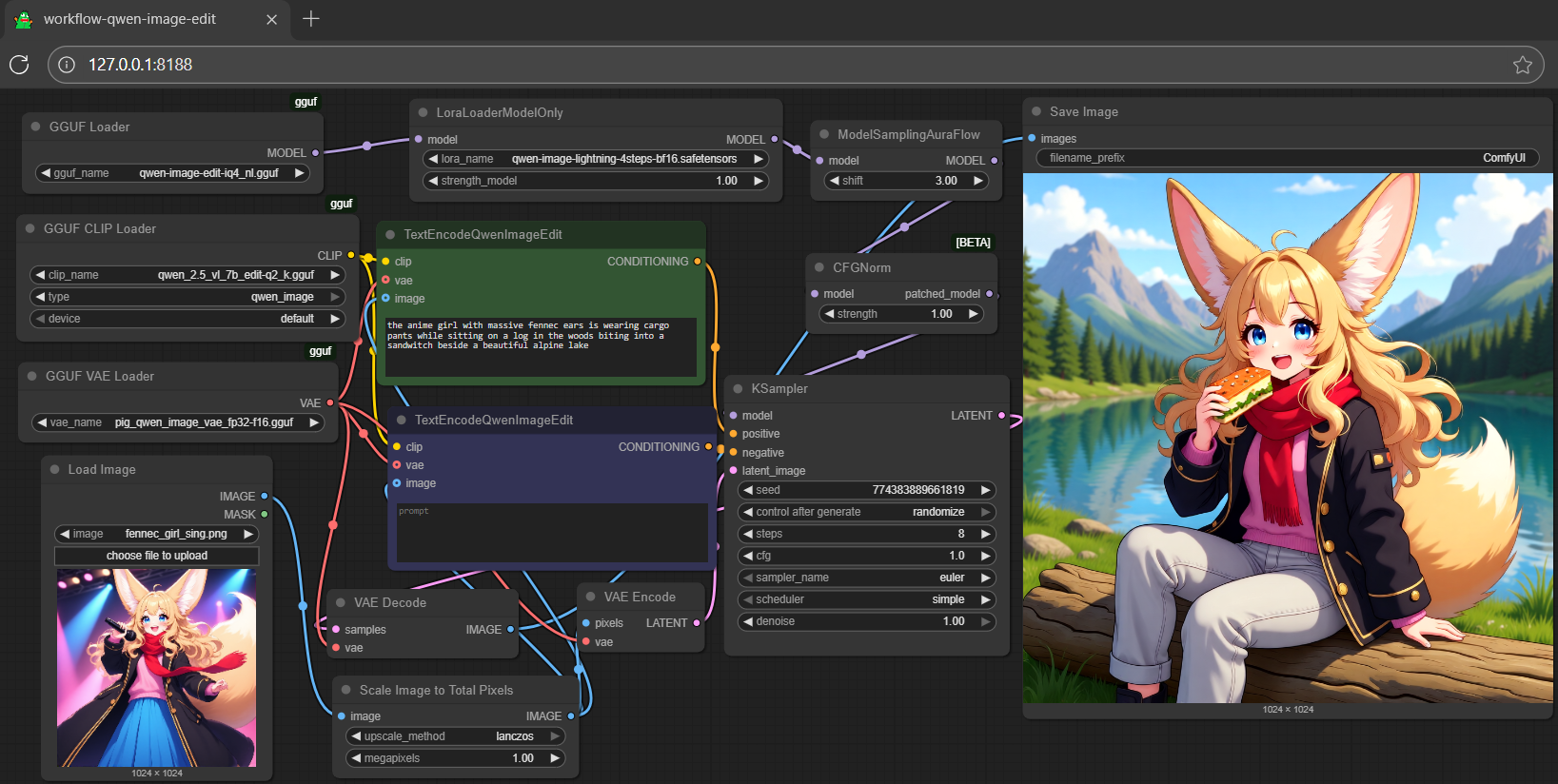
- Prompt
- the anime girl with massive fennec ears is wearing a maid outfit with a long black gold leaf pattern dress and a white apron mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive stuff everywhere
run it with diffusers
- might need the most updated diffusers; for i quant support, should after this commit; install the updated git version diffusers by:
pip install git+https://github.com/huggingface/diffusers.git
- see example inference below (edit it if needed):
import torch, os
from diffusers import QwenImageTransformer2DModel, GGUFQuantizationConfig, QwenImageEditPipeline
from diffusers.utils import load_image
model_path = "https://huggingface.co/calcuis/qwen-image-edit-gguf/blob/main/qwen-image-edit-iq4_nl.gguf"
transformer = QwenImageTransformer2DModel.from_single_file(
model_path,
quantization_config=GGUFQuantizationConfig(compute_dtype=torch.bfloat16),
torch_dtype=torch.bfloat16,
config="callgg/image-edit-decoder",
subfolder="transformer"
)
pipeline = QwenImageEditPipeline.from_pretrained("callgg/image-edit-decoder", transformer=transformer, torch_dtype=torch.bfloat16)
print("pipeline loaded")
pipeline.enable_model_cpu_offload()
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/cat.png")
prompt = "Add a hat to the cat"
inputs = {
"image": image,
"prompt": prompt,
"generator": torch.manual_seed(0),
"true_cfg_scale": 2.5,
"negative_prompt": " ",
"num_inference_steps": 20,
}
with torch.inference_mode():
output = pipeline(**inputs)
output_image = output.images[0]
output_image.save("output.png")
print("image saved at", os.path.abspath("output.png"))
reference
- base model from qwen
- diffusers from huggingface
- comfyui from comfyanonymous
- gguf-node (pypi|repo|pack)
- gguf-connector (pypi)